강의 개요
- 강의명: [#10774] SQL Server 2012 기본 쿼리(TSQL 기초) – Microsoft SQL Server 2012 기초
- 장소: 웹타임
- 일시: 2014-03-25
- 자세히: 70-461 Querying Microsoft SQL Server 2012(MOC 10774A)
※ 수업(Module 8)에 본격적으로 들어가기 전에 INSERT 등의 DML을 훑어봄
함수
- 함수를 많이 알면 좋음
- 종류
- 스칼라 함수
- 1등만 기억하는 더러운 세상
- MS 기술에서 스칼라값을 많이 사용
- 집계와 관련된 함수
- 자연적으로 계산을 해줌
- cos, tan 등을 알아서 계산해줌
- 창과 관련된 함수
- 창의 모양 변경 등
- Rowset
- 임시로 데이터를 저장하는 함수
- Table 형식으로…
- 임시로 데이터를 저장하는 함수
- 스칼라 함수
Scalar 함수
- 오로지 하나의 값만 리턴
- Date and Time
- Mathmetical …
- 등등
여러 가지 함수
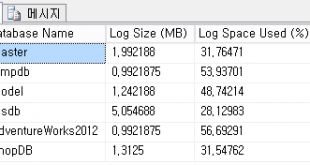
▼ master 등의 시스템 데이터베이스의 시스템 함수는 기본적인 DB의 것과 조금 다름.
메타데이터를 배울 때 더 볼 예정

집계 함수
▼ 평균, 카운트, 최대, 최소, 합계를 많이 사용!

▼ 수치 연산 함수

▼ Ltrim()과 같은 경우에는 공백을 제거하고 이름을 넣을 때 ^^

▼ 현재 시간 등을 출력하기

※ 실무에서는 GETDATE()를 많이 쓴다.
▼ 서버의 시간을 저장하는 것을 잘 응용하면 좋다.

▼ ‘-‘를 붙이지 않아도 잘 동작.

※ 옛날 버전 SQL Server를 사용 중이라면 CAST()를 사용해야 한다.
▼ 한글 윈도우의 한글 SQL Server라서 다른 나라 형식으로 DATE를 표시할 수 없을 수 있음

▼ 태어난 지 몇일?

▼ 날짜 만지기

▼ 날짜가 잘못 들어가있죠?

※ 3, 7번째 데이터가 잘못되어 있음
▼ 날짜 형식으로 표시하고, 잘못된 3, 7번만 NULL로 표시

▼ CONVERT보다 CAST를 쓰는 것을 권장 ^^

▼ 특정 기간에 판매된 데이터의 custid 출력

▼ 마지막 날을 출력하는 EOMONTH ^^

▼ 이 달의 첫날과 마지막 날 출력

▼ 마지막 5일을 갖고 오라고 했으니까… EOMONTH에서 5보다 작은 것을 선택

▼ JOIN 다음에 ON이 나오는 것이 익숙치 않음. WHERE까지는 바로 나오는데…

많이 해볼 수 밖에…
▼ 이름 중에 콤마의 위치를 찾기 위해 CHARINDEX() 함수 사용

▼ 응용하여 lastname만 출력해봄

▼ ‘,’을 공백으로 바꿔보고, lastname을 표시해 보기

▼ ‘\C000000’ 형식으로 표시하기

▼ 이름 중에서 ‘a’가 몇 개 들어가는가?

▼ a가 많은 순으로 정렬

※ 스팸 메일 Filtering 등에서 활용하면 좋을 듯! ‘광고’ ‘대출’ 등…
☆ SQL Server는 ‘ ‘ 안에 들어간 것만 대소문자 구분을 함
- 그래서 UPPER이나 LOW를 잘 쓰면 좋음
- MS는 대소문자 구분을 싫어함
- 띄어쓰기도 마찬가지
▼ 아하! a를 없앤 뒤에 전체 글자길이에서 없앤 글자길이를 빼서 a의 글자수를 계산하는구나…

※ 1차원적으로 그냥 a의 개수를 추출하는 것보다 빠른 방법인 듯.
Inplicit and Explicit Data Type
- 형변환
- CONVERT보다 CAST를 권장
- SQL Server 2000도 CAST를 먹음
- 2005부터는 CONVERT도 먹음
CAST
문법
- CAST aaa AS bbb
- aaa는 value, bbb는 datatype
- 날씨를 숫자로 바꾸는 것은 불가능
- 예외는 있음(숫자만 들어갈 때)
- 명시적으로 형변환 못한다고 알려줌
PARSE
- SQL Server 2012에서 새로 나옴
- .NET Framework 4 이전이라면 사용하지 않는 것이 좋음
- 다국어로 바꿀 수 있게 도와줌
문법
SELECT PARSE(’02/12/2012′ AS datetime2 USING ‘en-US’) AS parse_result;
(닷넷에 있는 기능을 활용하는 것)
TRY_PARSE
- TRY이니까 기능이 적용되는지 따짐
- 바꿀 수 있으면 값을 출력, 아니면 NULL
☆ CAST를 추천합니다.
ISNUMERIC
- 숫자, 화폐 = 1(True)
- 글씨 = 0(False)
- 숫자로 입력받을 때
- 나이
IIF
- 삼항연산자
- 단순비교
- 특정 컬럼과 무언가를 비교
- 참이면 첫번째 컬럼, 거짓이면 두번째 컬럼을 처리
- CASE로 바꿀 수 있음
☆ CASE는 될 수 있으면 딱 맞아떨어질 때 쓰는 것이 좋음
CHOOSE
- 여러 선택사항 중에서 선언한 것에 맞는 것 선택
NULL with ISNULL
- NULL값도 캐스팅이 된다.
- NULL값을 보면 ‘N/A’로 바꾸는 예제
COALESCE
- NULL값을 만나면 아무것도 리턴하지 않음
- ISNULL은 NULL로 리턴
- 연산을 할 때 많이 쓰임
- 문자열을 합치는 작업 등
NULLIF
- 첫번째 컬럼과 두번째 컬럼이 같으면 NULL
- 첫번째: 현재값
- 두번째: 기준값
- 다르면 해당 값을 표시
- 우리 회사 일꾼들의 목표달성 결과 비교 가능
- Goal이 90일 때
- 결과가 90이면 NULL, 100이면 출력, 80이면 출력
▼ NULL이 보기 싫다면?

▼ 위와 동일하게 91개 행을 출력하지만 NULL은 표시하지 않음

▼ 연습문제~ 스스로 잘 해냄 ^^

※ CAST와 CONVERT를 모두 활용(동일한 결과)
☆ 너무 많은 데이터가 있는 DB의 경우 TOP(10) 등을 활용
▼ 스스로 해봤지만 완벽하지 못했던 문제. 이게 정답.

▼ 아… 어렵다.

☆ -, (, ) 문자를 모두 없앤 결과 출력.(IP주소 형식은 과감히 NULL로…)
▼ 삼항연산

☆ 복잡한 식은 괄호로 묶어 주세요. 탭과 스페이스바를 잘 활용하길.
▼ 지역이 NULL이면 Other

▼ COALESCE와 ISNULL을 비교…

집계 함수
- COUNT 등
- 그룹핑과 함께 사용
- 엑셀처럼 SUM, MIN, MAX 등 사용
☆ 집계 함수에서 NULL 데이터는 뺍니다!
- 앞에서 배운 NULL 관련 함수를 사용
GROUP BY
- WHERE 구문 다음
- GROUP BY를 하는 컬럼들이 SELECT 다음에도 나와야 함
- 끼리끼리 묶어놓고 나중에 어떻게 처리할지 결정
HAVING
- GROUP BY의 필터링
- WHERE은 Table의 필터링!
▼ GROUP BY 실습

▼ GROUP BY에서 없는 컬럼을 SELECT에서 보여줄 때에도 오류!

※ 51행을 GROUP BY o.custid, c.contactname, c.city; 로 바꿔주면 실행됨
▼ 실행 순서를 기억하자

▼ 다이어그램을 잘 봐야. 조인 순서

▼ 첫번째날 했던 실습을 그룹핑으로!

※ GROUP BY를 하니까 DISTINCT가 된 것.
- 아예 끼리끼리 묶어서 중복된 것을 해결
- CASE 구문이 훨씬 쉽구나…;
▼ 집계함수가 컬럼명에 오면 GROUP BY에서 써주지 않아도 됨

▼ 아하! 연도에 100을 곱하면 201400 처럼 되니 월을 더하면 딱이겠구만.

▼ 다이어그램으로 확인

▼ +_+ 어렵다~
LEFT OUTER JOIN의 경우 앞의 테이블을 기준으로 뒤의 테이블을 연결

☆ GROUP BY의 결과를 필터링하는 것이 HAVING
오늘은 중간 정도까지는 따라갔는데 그 이후에는 스스로 구문을 만들어내기가 힘들었다. 얼추 비슷하게 만든 것도 가끔 있었지만 정답과 일치하지 않는 경우가 많았다.
thanks to 김병진 이사님