강의 개요
- 강의명: [#10774] SQL Server 2012 기본 쿼리(TSQL 기초) – Microsoft SQL Server 2012 기초
- 장소: 웹타임
- 일시: 2014-03-25
- 자세히: 70-461 Querying Microsoft SQL Server 2012(MOC 10774A)
2일차: 별칭, 중복제거, CASE, 관계형 DB 개요, 정렬, NULL, 데이터 타입
어제 배운 것
☆ MS SQL은 저장소라고 생각 / 하드디스크 – 물리적 저장
- 데이터를 핸들링하는 언어 T-SQL
- 어제 배운 내용은 SELECT
- 화면에 뿌려주는 겁니다.
오늘 배워볼 것
- 별칭
- intellisense를 써서 편하니까 ^^
- 오늘은 별칭의 장점을 최대한 활용해보자
- 중복제거
- DISTINCT
- CASE
- 데이터가 정확하게 맞아 떨어지는 것
- 관계형 데이터베이스
- 테이블을 여러 개 나눠서 저장
- 그 테이블들을 관계를 맺어서 하나의 테이블로 가져오기
- 정렬
- 내가 원하는 행을 가져와서 처리
- NULL
Joins
- 대부분 Inner Joins를 씀
- Outer Joins는 늘리는 것
- Cross Joins는 n개의 Table을 모두 합치는 것
- Self-Joins는 회사 조직도 만들 때…
- FROM 다음에 오는 구문!
- Virtual Table
- Table을 n개 연결시켜 1개의 가상 테이블로 만든다
- sub-query와는 좀 다름
- 증가된 값이 나올 수도, 축소된 값이 나올 수도 있음
- 곱하기를 어떻게 하느냐에 따라 값이 많이 다름
Inner Joins
- 공통적인 것을 조인
기본 문법(ANSI SQL-92)
SELECT …
FROM Table1 JOIN Table2
ON <on_predicate>
(T-SQL에서는 JOIN 앞에 Inner, Outer, Cross를 붙일 수 있음)
- ON 다음에 관계를 맺음
- 공통적인 것을 찾으면 됨
- 교집합 ^^
문법
FROM t1 JOIN t2
ON t1.column = t2.column
(t1.column과 t2.column의 공통된 녀석을 갖고옴)
- JOIN만 해도 Inner Joins로 인식
- 추후에 가독성을 높이려면 명시적으로 INNER JOIN으로 표기하면 좋음
- DISTINCT를 써서 모두 중복제거 가능
Outer Joins
- 가상의 테이블을 만들 때 첫번째와 두번째 테이블을 비교하는 것은 맞음, 교집합(공통적인 것)을 포함해 좌측 또는 우측을 가져옴
- 데이터가 없는 것은 NULL로 처리
- FULL OUTER JOIN은 잘 쓰지 않음(나중에 배울 Union?을 쓰는 것이 낫다고 함)
- ‘공통된 것을 포함한 A테이블을 갖고 오고 싶다.’일 때 사용
Cross Joins
- 곱하기
- 첫번째 + 두번째 테이블 합치기
- 무식하게 많이 표시
문법
SELECT …
FROM t1 CROSS JOIN t2
Self Joins
- 조직도 만들 때
- 자기 자신을 다시 한번 관계를 맺어서 나를 기준으로 무언가를 다시 생성할 때
- 나와 나 끼리
문법
SELECT …
FROM T1 AS t1 JOIN T AS t2
ON t1.Col1 = t2.Col2;
- 컴퓨터는 문자보다 숫자를 빨리 처리하니까… 순서를 주게 됨
☆ 빨리 데이터를 가져다주는 쿼리문이 좋아요!
▼ MS SQL 자체적으로 ERD 같은 기능을 제공

▼ 원하는 테이블들을 선택

▼ 여기서 뭔가 변경하면 바로 적용됨!! 무서워…

※ 선을 보세요!
▼ 원하는 항목이 어디 있는지 찾을 때 다이어그램을 활용!

▼ 연결된 선을 선택해서 속성을 누르면…

▼p와 c의 공통된 것 중에서 p의 productname과 c.categoryname을 출력

▼ 구문은 문제가 없으나 어떤 custid를 출력해야 하는지 모름

▼ 다이어그램을 보면 custid가 양쪽에 다 있음.

▼ 이렇게 Sales.Customers.custid 라고 구체적으로 적어주면 실행됨

▼ 왜 오류가 날까? 별칭을 바꿨다면 그것을 적어줘야 한다!

c.custid로 바꿔주면 OK!
연결된 테이블을 만들때
- 가장 기준되는 값을 찾기(정규화를 거치면 나옴)
- 1을 기준으로 먼저 와야 할 순서를 정함
▼ INNER JOIN의 쓰임을 잘 보기

※ 크게 관련은 없지만 qty는 quantity(수량)라고 함
▼ 자기자신이 연결되있음

▼ 관리자명(manager id ; mgrid)을 출력하는 쿼리. 비교 대상을 어디에 두느냐에 따라서 결과가 달라짐.

▼ 22번이 없음. OUTER JOIN을 써야 함

▼ 22번 내용이 존재!

☆ 밖에 나가서도 INNER JOIN을 많이 사용
ORDER BY
- 순차 정렬 ASC
- ABCDE…
- ㄱㄴㄷㄹㅁ…
- 12345…
- 역순 정렬 DESC
- ASC의 반대
- ORDER BY 뒤에 아무것도 안쓰면 자동으로 ASC로 인식
문법
SELECT …
FROM table
ORDER BY 컬럼명1, 컬럼명2;
- ORDER BY는 제일 마지막에 실행된다
WHERE
- 조건에 해당되는 행만 갖고 온다.
- 2번째로 실행됨
- ‘행’의 필터링
- ‘SELECT 컬럼명’은 컬럼의 필터링이라고 보면 됨.
- SQL Server의 Indexes를 사용하는 것이 좋음
- SQL Server의 Index는 클러스터 인덱스와 논클러스터 인덱스가 있음
- 인덱스를 WHERE의 컬럼명으로 사용하면 좋음
- 서버의 부하를 줄여줌
- 쿼리 튜닝할때 WHERE 구문을 잘 봐야.
- WHERE에서 속도를 좌지우지함
- 범위를 찾을 때는 클러스터 인덱스가 좋음
- 특정 값을 콕 집어서 찾을 때는 논클러스터 인덱스가 좋음
- Primary Key는 자동으로 클러스터 인덱스로 잡힌다고 함
문법
SELECT 컬럼명
FROM table
WHERE 특정 컬럼 = ‘특정한 값’;
- WHERE orderdate > ‘20070101’;
- 2007년 1월 1일 이후 것을 다 가져와!
- WHERE orderdate >= ‘20070101’;
- 2007년 1월 1일부터 이후의 것을 다 가져와!
- WHERE orderdate >= ‘20070101’ AND orderdate <= ‘20080101’;
- 2007년 1월 1일부터 2008년 1월 1일 사이의 것을 다 가져와!
- BETWEEN으로 바꾸면 간결해지겠죠?
☆ 필터링을 잘못하면 데이터를 너무 많이 갖다주기 때문에 잘해야.
☆ AND, OR, NOT을 줄일 수 있는게 IN (여러 개의 값을 ‘또는’을 할 때…)
TOP
- Top 10! ^^
문법
SELECT TOP (N)
SELECT TOP (N) Percent
- TOP의 단점?
- ~에서 ~까지를 불러낼 때 문제가 생김
- 그래서 OFFSET-FETCH 사용
- SQL Server 2012에서만 먹는 구문임
NULL
- 공백이 아님
- 가계약 상태
- 미리 어느 정도 쓰겠다고 확보해 놓는 것
- 나중에 영향을 미치는 것이 덜함
- 알 수 없는 값이긴 하지만 언젠가 들어가겠다!
- NULL이 있는지 없는지 판단할 때 ‘=’ 기호 등으로 확인하지는 않는다
- IS NULL
- NULL 값이 있습니까?
- IS NOT NULLL
- NULL 값이 없습니까?
- IS NULL
▼ 아래 3줄을

▼ 아래와 같이 IN 으로 1줄로 다이어트!

☆ WHERE 는 FROM 테이블 중에서 필터링한 결과를 가져오는 것!
▼ 참 쉽죠?

▼ AND 기호를 써보면… 안나오네?

☆ Brazil, UK, USA가 모두 들어간 것이 아니기 때문!
▼ 이제 되는구나!

▼ IN으로도 ^^ 짧아서 좋구나

▼ Paris인 놈만 찾기

※ 불필요한 값까지 가져옴
▼ 이렇게 하면 OK!

▼ NULL인 것만 가져오기

※ NULL이 아닌 것만?
WHERE o.custid IS NOT NULL;
▼ 2008-04-01 이후 데이터 출력 – orderdate는 DESC로, custid는 ASC정렬

☆ Descending 내리다
☆ Ascending 오르다
▼ 쿼리 실행 순서를 알아야 에러가 나지 않음

※ 실행 순서를 잘 봅시다.
mgrlastname을 인식 못하는 것을 확인할 수 있음.
▼ 잘 되죠?

▼ 역순으로 TOP 20 출력

▼ SQL Server 2012에서 사용 가능한 OFFSET FETCH로?

▼ 하위 10% 출력

※ OFFSET FETCH는 Percent를 지원하지 않는다 – 왜? %는 상대적이기 때문.
SQL Data Types
☆ 변수는 바람둥이
☆ Binary Strings
- 이미지나 동영상
숫자
- 정수
- 실수
- 화폐 단위
문자
- 한 글자만 저장
- 문장을 저장
- 이미지
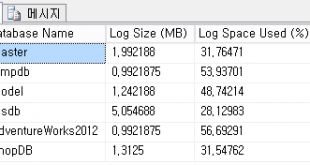
☆ SQL Server는 2005부터 한 컬럼에 최대 2GB까지 저장할 수 있음
- 실무에서는 10MB 이내라고 함
- 첨부파일에 이미지 저장할 때…
- 대용량 파일은 다른 방법으로!
☆ N을 붙이는 것은 유니코드로 처리하겠다는 의미.
형변환을 할 때는 CAST 명령 사용 / 또는 CONVERT 명령이 있음
▼ 정렬 방식 바꾸기

▼ 한국어를 쓸 때 정렬 방식이 이렇게 많아요…
그래서 윈도우 설정을 따라가요…

LIKE
- 어떤 글씨가 포함된 것을 갖고올 때
- LIKE ‘s%’
- s로 시작하는 모든 자료 갖고오기
- LIKE ‘Swe_t%’
- _에는 모든 문자 가능
- LILE ‘%Sweet%’
- Sweet가 포함된 모든 자료 갖고오기
- %, _, [, ] 등을 많이 씀
Date and Time
- DATETIME을 기억하라!
- 밀리세컨드까지 가져옴
- 2005부터 DATETIME을 많이 씀
- 1753년 1월 1일 이전을 표시할 수 없음
- 9999년 12월 31일 이후를 표시할 수 없음
- DATETIME2
- 2008부터 지원
- 0001년 1월 1일부터 9999년 12월 31일까지
- 100나노세컨드까지
- DATE
- 연월일만 저장
- 0001년 1월 1일부터 9999년 12월 31일까지
시간과 관련된 함수
- 데이터가 입력된 시간을 가져오는 작업이 많음
- GETDATE()
- GETUTCDATE()
- 표준시
- CURRENT_TIMESTAMP()
- ANSI 표준. 요즘은 이걸 권장함
함수 중에서 값을 반환하는 것
- DATENAME()
- ‘year’ ‘month’ 등
- 글자로 반환
- month에는 01~12 로 표현
- DATEPART()
- 숫자로 반환
▼ SQL Server의 데이터베이스 – 프로그래밍 기능 – 함수 – 시스템 함수 – 날짜 및 시간 함수에서 볼 수 있음

▼ 여기서 NULL을 빼고 싶은데…

※ 내일 함수 배우고 해볼 예정!
▼ 한번 아무렇게나 해봤는데… 맞는걸까? (아닌듯. 출력 결과를 살펴보니 정답 결과와 맞지 않다)

▼ ORDER BY를 적어주지 않으면 당연하지만 contactname으로 정렬되지 않음

thanks to 김병진 이사님