강의 개요
- 강의명: [#10774] SQL Server 2012 기본 쿼리(TSQL 기초) – Microsoft SQL Server 2012 기초
- 장소: 웹타임
- 일시: 2014-03-25
- 자세히: 70-461 Querying Microsoft SQL Server 2012(MOC 10774A)
오늘 배울 것
- Subqueries 하위 쿼리
- SELECT와 WHERE로만 쿼리했던 것을 다른 방법들로 시도해 보자
- 쿼리 안에 또 다른 쿼리를 만들어 놓고 씀
- 보통은 JOIN 구문과도 이야기를 많이 함
- SELECT 안에 SELECT를 또 던질 수 있음
- JOIN보다 Subqueries의 속도가 빠른 경우가 있다
- UNION
- 함수의 완성
- 피벗팅
- 메타 데이터
- 알아두면 도움이 됨
- 잘 몰라도… GUI로 메타 데이터를 볼 수 있으니까
Subqueries
Scalar Subqueries
- 다른 테이블의 데이터를 갖고올 때 사용
- JOIN 구문으로도 쓸 수 있지만 좀 더 빠르고 쉽게 결과를 도출할 수 있다
- 한 개의 값만 리턴
Multi-Valued Subqueries
- 여러 개의 값을 가져옴
- IN 이라는 구문을 사용
Correlated Subqueries
- 상관 하위 쿼리?
- 일반적으로 SELF JOIN과 관련성이 있음
- 하나의 값만 갖고 오는 경우 SELF JOIN으로 바꿀 수 없음
※ 하나의 값만 가져오는 하위 쿼리는 JOIN으로 가져오기 힘듦
EXISTS
- 있으면 참, 없으면 거짓
▼ TOP(1)과 ORDER BY desc로 정렬한 마지막 데이터 가져오기는 1개의 값만 가져오게 됨.
우리가 원하는 결과는 마지막 날에 결제한 데이터(4개) 전부이므로 위의 방법을 쓰는 것이 옳음

▼ 아… 이럴 때 사용하는구나

▼ = 구문으로는 하나의 값만 반환하는 경우에 쓸 수 있으므로 IN 구문을 활용해야 함! (위쪽 스크린샷으로)

▼ 순서를 알아야…

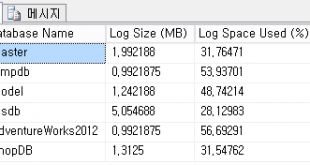
☆ 합계에서 전체를 가져와서 나눠야 Percentage를 구할 수 있기 때문
▼ JOIN 문법으로는 결과가 정확하게 나오지 않는 경우가 있다!

▼ 쇼핑몰 등에서 구매 기록이 없는 분께는 쿠폰을 주지 않거나 할 수 있음

※ 하위쿼리나 하위 상관 쿼리를 할 때 순서를 기억해야 함
▼ 회원별 마지막 구매 날짜 가져오기

▼ 이번에도 주문 데이터가 없는 고객 리스트

테이블 연산
View
☆ 복잡한 쿼리문을 VIEW로 갖고 있으면 쿼리문이 단순해질 것!
☆ JOIN을 포함한 복잡한 구문의 결과를 테이블로 갖고 나중에 그 테이블을 활용
- 가상 테이블이기 때문에 제약 사항이 있음
※ 인덱스를 만들 수 있어서 많이 씀
▼ 개체 탐색기에서 보이는 뷰들

▼ 간단하게 호출 가능
▼ 뷰에 없는 컬럼은 호출 불가

TVFs(Table-Valued Functions)
- 테이블 반환 함수(테이블 값 함수)
- 매개 변수(Parameters)는 @ 기호 사용
Derived Tables
- SELECT로 현재 쓰는 것과 다른 데이터베이스와 관계를 맺을 수 있음
- 최신 버전이면 좋지만…
- 테이블 이름을 다른 것으로 가져다 놓고 쓰는 것
Common Table Expressions(CTE)
- 일반 테이블 연산식
- 2005 이상에서 사용
- Derived Tables보다 CTE를 권장
- 가상의 테이블을 만들 때
- 속도가 빠르다고 함
가상의 테이블에 대한 실습
▼아래와 같은 결과를 뷰로 만들기

▼ CREATE VIEW 하단에 방금 소스를 붙임

▼ 개체 탐색기에 나타남

▼ 뷰를 만들 때 ORDER BY 절을 사용할 수 없음

▼ 이렇게 하면 ORDER BY 절을 사용 가능

▼ CASE 구문의 경우 별칭을 만들어줘야 함

▼ FROM 내부에 이렇게 쿼리문으로 가져오고, 자기 자신의 것을 호출

▼ 가상 테이블에서 만든 결과 응용하기

▼ 크게 두 그룹으로 묶어서 생각0

▼ CTE(Common Table Expressions) 활용

▼ 선택된 salesamt2008는 내부에서 쓸 수 있는 별칭.

▼ 연결해서 보기

▼ 테이블 반환 함수는 개체 탐색기에서 여기에 있음

▼ 개체 탐색기에서 수정을 통해 해당 함수의 내용을 살펴볼 수 있음

UNION
- 두 개의 테이블을 합치는 것
- 테이블, 컬럼명은 달라도 됨
- 순서는 두 개의 테이블이 같아야 함
- 두 개의 테이블이 똑같이 생겨야 한다.
- 컬럼의 순서와 데이터 타입이 같으면 됨
- DISTINCT를 하고 가져옴
※ CROSS JOIN은 달라도 괜찮지만 UNION은 타입이 같아야 함
UNION ALL
- DISTINCT 하지 않고 가져옴(UNION과 다른 점)
INTERSECT
- UNION인데 둘 중에 중복된 것만 가져옴
EXCEPT
- 중복된 것 말고 한쪽을 가져옴
APPLY
- 테이블 반환 함수와 CROSS JOIN 하는 역할
OUTER APPLY
- 테이블 반환 함수에 LEFT OUTER JOIN을 함
▼ UNION 예제(전)

▼ UNION 예제(후)

▼ UNION 시 ORDER BY를 쓰면 안되기 때문에 하위쿼리로 넣음

▼ 아직까지는 DISTINCT 한 것과 HAVING을 사용한 것이 결과가 동일

▼ COUNT를 할 때는 WHERE로 처리할 수 없으므로 GROUP BY로 …

WINDOW 함수
- 어디서부터 어디까지의 ROWS를 가져올 것인지를 정의하고 파티션으로 끊어 버림
- 같은 회사지만 영업부, 총무부 등으로 나눠져 있는 것처럼 분할
- 데이터를 가져와 분할해서 보는 방법
OVER
- 파티션된 뷰를 쓰거나 OVER를 씀
- 창을 분할하고 제어
OFFSET
- SELF JOIN 이기 때문에 자기자신과 비교
▼ OVER 사용해 보기

▼ 이번에는 순위 출력

※ 순위가 같은 녀석도 있음(orderdate 기준이니까)
▼ custid를 기준으로 결과를 잘라줌

▼ 고객 내에서도 RANK 별로 분류

▼ 하위 쿼리를 통해 내부의 overrank에 접근

☆ 어떤 식으로 나누는 지를 알면 편할 듯
PIVOT
- 행과 열을 바꾸는 녀석!
UNPIVOT
GROUPING
- GROUP BY 다음에
▼ 하단의 기능들은 2012 이상에서 사용
GROUPING SET
CUBE and ROLLUP
- 통계에 관한 것을 묶음으로 갖고 있음
- 2012 이상에서 지원
GROUPING_ID
- 그루핑에 대한 내부적인 값을 리턴
- 순서에 관련한 부분을 숫자로 리턴
- 카테고리를 문자열이 아니라 숫자값으로 리턴
Thanks to 김병진 이사님