이렇게 마구 긁어와도 되는지 모르겠지만… 일단 인용한 문장 하나하나마다 출처가 명시되어 있어서 수집 기록을 남길 겸 해서 포스팅. 인용한 내용이 문제가 되면 바로 삭제 예정.
Exchange Server 2013의 메일박스 서버 관련 정보 모음
사서함 서버
Microsoft Exchange Server 2010에서 사서함 서버 역할은 사서함 및 공용 폴더 데이터베이스를 모두 호스트하고 전자 메일 메시지 저장소도 제공했습니다. 이제 Exchange Server 2013에서 사서함 서버 역할에는 클라이언트 액세스 프로토콜, 전송 서비스 사서함 데이터베이스 및 통합 메시징 구성 요소도 포함됩니다.
Exchange 2013에서는 사서함 서버 역할이 다음과 같은 프로세스에서 Active Directory, 클라이언트 액세스 서버 및 Microsoft Outlook 클라이언트와 직접 상호 작용합니다.
- 사서함 서버는 Active Directory의 받는 사람, 서버 및 조직 구성 정보에 액세스하기 위해 LDAP를 사용합니다.
- 클라이언트 액세스 서버는 클라이언트의 요청을 사서함 서버에 보내고 사서함 서버의 데이터를 클라이언트에 반환합니다. 또한 클라이언트 액세스 서버는 NetBIOS 파일 공유를 통해 사서함 서버의 OAB(온라인 주소록) 파일에 액세스합니다. 클라이언트 액세스 서버는 클라이언트와 사서함 간에 메시지, 약속 있음/없음 데이터, 클라이언트 프로필 설정 및 OAB 데이터를 전송합니다.
- 방화벽 내부에 있는 Outlook 클라이언트는 클라이언트 액세스 서버에 액세스하여 메시지를 보내고 검색합니다. 방화벽 외부에 있는 Outlook 클라이언트는 HTTP프록시 구성 요소를 통해 RPC 를 사용하는 외부에서 Outlook사용을 통해 클라이언트 액세스 서버에 액세스할 수 있습니다.
- 공용 폴더 사서함에는 클라이언트가 방화벽 안쪽에 있거나 바깥쪽에 있거나 관계없이 RPC over HTTP를 통해 액세스할 수 있습니다.
- 관리자 전용 컴퓨터는 Microsoft Exchange Active Directory 토폴로지 서비스에서 Active Directory 토폴로지 정보를 검색합니다. 또한 이 컴퓨터는 전자 메일 주소 정책 정보와 주소 목록 정보를 검색합니다.
- 클라이언트 액세스 서버는 LDAP 또는 NSPI(Name Service Provider Interface)를 사용하여 Active Directory 서버에 연결하고 사용자의 Active Directory 정보를 검색합니다.
사서함 및 클라이언트 액세스 서버 상호 작용 및 아키텍처

자세한 내용은 Exchange 2013의 새로운 기능의 “Exchange 2013 아키텍처” 섹션을 참조하십시오.
출처: <http://technet.microsoft.com/ko-kr/library/jj150491(v=exchg.150).aspx>
사서함 데이터베이스는 사서함이 만들어지고 저장되는 세분성 단위입니다. 사서함 데이터베이스는 Exchange 데이터베이스(.edb) 파일로 저장됩니다. Microsoft Exchange Server 2013에서는 각 사서함 데이터베이스에 구성할 수 있는 고유한 속성이 있습니다.
출처: <http://technet.microsoft.com/ko-KR/library/jj150580(v=exchg.150).aspx>
Exchange 2013 아키텍처
이 전 버전의 Exchange는 당시의 특정한 기술적 제약 조건에 맞게 최적화되고 설계되었습니다. 예를 들어 Exchange 2007을 개발할 때의 주요 제약 조건 중 하나는 CPU 성능이었습니다. 이 제약 조건을 완화하기 위해 Exchange 2007은 여러 서버 역할로 분할되어 서버 분리를 통해 확장을 지원했습니다. 그러나 Exchange 2007과 Exchange 2010에서 서버 역할은 밀접하게 결합되어 있었습니다. 역할이 밀접하게 결합된 경우 버전 종속성, 지역 선호도(특정 사이트에 모든 역할 필요), 세션 선호도(비용이 많이 드는 계층 7 하드웨어 부하 분산 필요) 및 네임스페이스 복잡성을 비롯한 몇 가지 단점이 있었습니다.
오늘날 CPU 처리 능력은 비용이 크게 낮아졌으므로 더 이상 제약 요소가 되지 않습니다. 이 제약 조건이 제거됨에 따라 Exchange 2013의 기본 디자인 목표는 간편한 확장, 하드웨어 이용률 및 오류 격리가 되었습니다. Exchange 2013에서는 서버 역할의 수를 클라이언트 액세스 서버 역할과 사서함 서버 역할의 두 가지로 줄였습니다.
현 재 Edge 전송 서버의 Exchange 2013 버전은 없습니다. Edge 전송 서버가 필요한 경우 해당 경계 네트워크에 Exchange 2007 또는 Exchange 2010 Edge 전송 서버를 설치할 수 있습니다. 자세한 내용은 Exchange 2013에서 Exchange 2010 또는 2007 Edge 전송 서버 사용을 참조하십시오.
사 서함 서버에는 Exchange 2010에 있는 모든 일반 서버 구성 요소가 포함됩니다. 클라이언트 액세스 프로토콜, 전송 서비스, 사서함 데이터베이스 및 통합 메시징이 이에 해당합니다. 사서함 서버는 해당 서버에서 활성 사서함에 대한 모든 작업을 처리합니다. 클라이언트 액세스 서버는 인증, 제한된 리디렉션 및 프록시 서비스를 제공합니다. 클라이언트 액세스 서버 자체는 데이터 렌더링을 수행하지 않습니다. 클라이언트 액세스 서버는 상태 비저장 씬 서버입니다. 클라이언트 액세스 서버에서는 어떠한 항목도 큐에 추가되거나 저장되지 않습니다. 클라이언트 액세스 서버는 일반적인 클라이언트 액세스 프로토콜을 모두 제공합니다. HTTP, POP, IMAP 및 SMTP가 이에 해당합니다.
이 새 아키텍처에서는 클라이언트 액세스 서버 및 사서함 서버가 “느슨하게 결합”되어 있습니다. 특정 사서함에 대한 모든 처리 및 작업은 사서함이 있는 활성 데이터베이스 복사본을 보관하는 사서함 서버에서 이루어집니다. 모든 데이터 렌더링 및 데이터 변환은 활성 데이터베이스 복사본에 로컬로 수행되므로 클라이언트 액세스 서버 및 사서함 서버 간의 버전 호환성 문제가 없습니다.
Exchange 2013 아키텍처에는 다음과 같은 이점이 있습니다.
- 버전 업그레이드 유연성 더 이상 경직된 업그레이드 요구 사항이 없습니다 .클라이언트 액세스 서버는 사서함 서버와 관련하여 원하는 순서로 독립적으로 업그레이드할 수 있습니다 .
- 세션 무관 Exchange 2010 에서는 클라이언트 액세스 서버 역할에 대한 세션 선호도가 여러 프로토콜에 필요했습니다 . Exchange 2013 에서는 클라이언트 액세스 및 사서함 구성 요소가 동일한 사서함 서버에 있습니다. 클라이언트 액세스 서버가 사용자의 모든 연결을 특정 사서함 서버로 프록시 처리하므로 클라이언트 액세스 서버에서 세션 선호도가 필요하지 않습니다. 따라서 최소 연결이나 라운드 로빈과 같은 부하 분산 기술에서 제공하는 방법을 사용하여 클라이언트 액세스 서버에 대한 인바운드 연결의 균형을 맞출 수 있습니다.
- 배포 간소화 Exchange 2010사이트 복구 디자인에서는 인터넷 프로토콜 네임스페이스 2 개 , Outlook Web App대체를 위한 네임스페이스 2개, 자동 검색을 위한 네임스페이스 2개, RPC 클라이언트 액세스를 위한 네임스페이스 2개 및 SMTP를 위한 네임스페이스 1개 등 최대 8개의 네임스페이스가 필요했습니다. Exchange 2003 또는 Exchange 2007에서 업그레이드한 경우에는 레거시 네임스페이스도 필요했습니다. Exchange 2013에서는 네임스페이스의 최소 개수가 2개로 감소했습니다. Exchange 2007을 함께 사용하는 경우 레거시 호스트 이름을 계속 만들어야 하지만 Exchange 2010을 함께 사용하거나 새 Exchange 2013 조직을 설치하는 경우 필요한 최소 네임스페이스 수가 클라이언트 프로토콜 및 자동 검색에 대해 하나씩 2개입니다. SMTP 네임스페이스가 필요할 수도 있습니다.
이러한 아키텍처 변경 사항으로 인해 클라이언트 연결이 약간 변경되었습니다. 첫째, RPC는 더 이상 지원되는 직접 액세스 프로토콜이 아닙니다. 따라서 모든 Outlook 연결은 RPC over HTTP(“외부에서 Outlook 사용”이라고도 함)를 사용하여 수행해야 합니다. 언뜻 보기에 이것은 제한 같지만 실제로는 몇 가지 추가된 이점이 있습니다. 가장 분명한 이점은 클라이언트 액세스 서버에 RPC 클라이언트 액세스 서비스가 존재할 필요가 없다는 것입니다. 따라서 사이트 복구 솔루션에 일반적으로 필요한 네임스페이스 2개가 줄어듭니다. 또한 더 이상 RPC 클라이언트 액세스 서비스에 대한 선호도를 제공할 필요가 없습니다.
둘째, Outlook 클라이언트가 더 이상 Exchange의 모든 이전 버전처럼 서버 FQDN에 연결하지 않습니다. Outlook은 자동 검색을 사용하여 사서함 GUID, @ 기호 및 사용자 기본 SMTP 주소의 도메인 부분으로 구성된 새로운 연결 지점을 만듭니다. 이 간단한 변경 덕분에 “관리자가 사서함을 변경했습니다. 다시 시작하십시오.”라는 원치 않는 메시지가 거의 나타나지 않게 되었습니다. Exchange 2013에서는 Outlook 2007 이상 버전만 지원됩니다.
사서함 구성 요소의 고가용성 모델은 Exchange 2010 이후 크게 변경되지 않았습니다. 고가용성의 단위는 여전히 DAG(데이터베이스 가용성 그룹)입니다. DAG는 여전히 Windows Server 장애 조치(failover) 클러스터링을 사용합니다. 연속 복제에서는 여전히 파일 모드 및 차단 모드 복제를 모두 지원합니다. 그러나 몇 가지 기능이 향상되었습니다. 트랜잭션 로그 코드가 개선되고 수동 데이터베이스에 대한 검사점 깊이가 증가한 결과 장애 조치(failover) 시간이 감소했습니다. Exchange 저장소 서비스가 관리 코드로 재작성되었습니다(이 항목 뒷부분에 있는 “관리되는 저장소” 섹션 참조). 이제 각 데이터베이스가 자체 프로세스로 실행되므로 단일 데이터베이스의 저장소 문제를 격리할 수 있습니다.
출처: <http://technet.microsoft.com/ko-KR/library/jj150540(v=exchg.150).aspx>
전송 파이프라인
전송 파이프라인은 다음 서비스로 구성됩니다.
- 클라이언트 액세스 서버의 프런트 엔드 전송 서비스 이 서비스는 Exchange 2013 조직의 모든 인바운드 및 아웃바운드(선택 사항) 외부 SMTP 트래픽에 대한 상태 비저장 프록시로 작동합니다. 프런트 엔드 전송 서비스는 메시지 내용을 검사하지 않고 사서함 서버의 사서함 전송 서비스와 통신하지 않으며 메시지를 로컬로 대기시키지 않습니다.
- 사서함 서버의 전송 서비스 이 서비스는 이전 버전의 Exchange에 제공되던 허브 전송 서버 역할과 거의 동일합니다. 전송 서비스는 조직의 모든 SMTP 메일 흐름을 처리하고, 메시지 분류를 수행하고, 메시지 콘텐츠 검사를 수행합니다. 이전 버전의 Exchange와 달리 전송 서비스는 사서함 데이터베이스와 직접 통신하지 않습니다. 이 작업은 이제 사서함 전송 서비스에 의해 처리됩니다. 전송 서비스는 사서함 전송 서비스, 전송 서비스, 프런트 엔드 전송 서비스 및 구성에 따라 Edge 전송 서버의 전송 서비스 간에 메시지를 라우팅합니다. 사서함 서버의 전송 서비스에 대해서는 이 항목의 뒷부분에서 보다 자세히 설명합니다.
- 사서함 서버의 사서함 전송 서비스 이 서비스에는 다음 개별 서비스 두 개가 포함됩니다. 사서함 전송 제출 서비스 및 사서함 전송 배달 서비스. 사서함 전송 배달 서비스는 로컬 사서함 서버나 다른 사서함 서버의 전송 서비스에서 SMTP 메시지를 수신하고 Exchange RPC(원격 프로시저 호출)를 통해 로컬 사서함 데이터베이스에 연결하여 메시지를 배달합니다. 사서함 전송 제출 서비스는 RPC로 로컬 사서함 데이터베이스에 연결하여 메시지를 검색하고 SMTP를 통해 로컬 사서함 서버나 다른 사서함 서버의 전송 서비스에 메시지를 전송합니다. 사서함 전송 제출 서비스는 전송 서비스와 동일한 라우팅 토폴로지 정보에 액세스할 수 있습니다. 프런트 엔드 전송 서비스와 마찬가지로 사서함 전송 서비스도 메시지를 로컬 큐에 넣지 않습니다.
- Edge 전송 서버의 전송 서비스 이 서비스는 사서함 서버의 전송 서비스와 매우 비슷합니다. 경계 네트워크에 Edge 전송 서버가 설치되어 있으면 인터넷에서 주고 받는 모든 메일이 전송 서비스 Edge 전송 서버를 통과합니다. 이 서비스에 대해서는 이 항목의 뒷부분에서 더 자세하게 설명합니다.
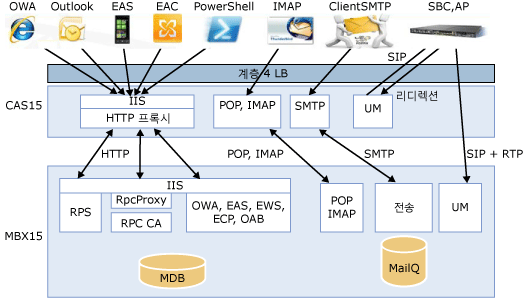
다음 그림에서는 Exchange 2013 전송 파이프라인의 구성 요소 간 관계를 보여줍니다.
Exchange 2013의 전송 파이프라인 개요

외부 보낸 사람의 메시지
조직 외부에서 보낸 메시지는 클라이언트 액세스 서버의 프런트 엔드 전송 서비스에 있는 수신 커넥터를 통해 전송 파이프라인으로 들어간 다음 사서함 서버의 전송 서비스로 라우팅됩니다.
경 계 네트워크에 Exchange 2013 Edge 전송 서버가 설치되어 있는 경우 조직 외부에서 보낸 메시지는 Edge 전송 서버의 전송 서비스에 있는 수신 커넥터를 통해 전송 파이프라인으로 들어갑니다. 그 다음에 메시지가 이동하는 위치는 내부 Exchange 서버가 구성된 방식에 따라 달라집니다.
- 같은 컴퓨터에 설치된 사서함 서버 및 클라이언트 액세스 서버 이 구성에서는 클라이언트 액세스 서버가 인바운드 메일 흐름에 사용됩니다 .메일은 Edge전송 서버의 전송 서비스에서 클라이언트 액세스 서버의 프런트 엔드 전송 서비스로 이동한 다음 사서함 서버의 전송 서비스로 이동합니다 .
- 다른 컴퓨터에 설치된 사서함 서버 및 클라이언트 액세스 서버 이 구성에서는 인바운드 메일 흐름에 대해 클라이언트 액세스 서버가 무시됩니다 .메일은 Edge전송 서버의 전송 서비스에서 사서함 서버의 전송 서비스로 이동됩니다 .
출처: <http://technet.microsoft.com/ko-kr/library/aa996349(v=exchg.150).aspx>
사서함 서버의 전송 서비스
Exchange 2013 조직에서 보내거나 받는 모든 메시지는 먼저 사서함 서버의 전송 서비스에서 분류되어야만 라우팅 및 배달될 수 있습니다. 분류된 메시지는 대상 사서함 데이터베이스, 대상 DAG(데이터베이스 사용 가능 그룹), Active Directory 사이트, Active Directory 포리스트 또는 조직 외부의 대상 도메인으로 배달하기 위해 배달 큐에 추가됩니다.
사서함 서버의 전송 서비스는 다음 구성 요소와 프로세스로 구성됩니다.
- SMTP 수신 전 송 서비스에서 메시지를 받으면 메시지 콘텐츠 검사가 수행되고 전송 규칙이 적용되며 사용 가능한 경우 스팸 방지 및 맬웨어 방지 검사가 수행됩니다. SMTP 세션에는 메시지를 수락하기 전에 메시지 콘텐츠의 유효성을 검사하기 위해 특정 순서로 함께 작동되는 일련의 이벤트가 있습니다. 메시지가 SMTP 수신을 통해 완전히 전달된 후 수신 이벤트나 스팸 방지 및 맬웨어 방지 에이전트에 의해 거부되지 않으면 전송 큐에 추가됩니다.
- 전송 전송은 메시지를 전송 큐에 넣는 프로세스입니다 .분류기는 분류할 메시지를 한 번에 하나씩 선택합니다 .전송은 다음 세 가지 방법으로 이루어집니다 .
- SMTP 수신에서 수신 커넥터를 통해
- Pickup 디렉터리나 Replay 디렉터리를 통해 이러한 디렉터리는 사서함 서버와 Edge 전송 서버에 있습니다. Pickup 디렉터리나 Replay 디렉터리에 복사되는 올바른 형식의 메시지 파일은 직접 전송 큐에 추가됩니다.
- 전송 에이전트를 통해
- 분류기 분류기는 전송 큐에서 한 번에 하나의 메시지를 선택합니다 .분류기는 다음 단계를 완료합니다 .
- 받는 사람 확인(최상위 주소 지정, 확장 및 분기 포함)
- 라우팅 확인
- 콘텐츠 변환
또 한 조직에서 정의한 메일 흐름 규칙이 적용됩니다. 분류된 메시지는 메시지의 대상을 기반으로 하는 배달 큐에 추가됩니다. 메시지는 대상 사서함 데이터베이스, DAG, Active Directory 사이트, Active Directory 포리스트 또는 외부 도메인에 의해 대기됩니다.
- SMTP 송신 메시지가 전송 서비스에서 라우팅되는 방식은 분류가 발생한 사서함 서버를 기준으로 메시지 받는 사람의 위치에 따라 다릅니다 .다음 위치 중 하나로 메시지를 라우팅할 수 있습니다 .
- 같은 사서함 서버의 사서함 전송 서비스
- 같은 DAG의 일부분인 다른 사서함 서버의 사서함 전송 서비스
- 다른 DAG, Active Directory 사이트 또는 Active Directory 포리스트에 있는 사서함 서버의 전송 서비스
- 같은 사서함 서버의 송신 커넥터, 다른 사서함 서버의 전송 서비스, 클라이언트 액세스 서버의 프런트 엔드 전송 서비스 또는 경계 네트워크의 Edge 전송 서버에 있는 전송 서비스를 통해 인터넷으로 배달
출처: <http://technet.microsoft.com/ko-kr/library/aa996349(v=exchg.150).aspx>
.EDB 파일
사서함 데이터베이스는 사서함이 만들어지고 저장되는 세분성 단위입니다. 사서함 데이터베이스는 Exchange 데이터베이스(.edb) 파일로 저장됩니다.
출처: <http://technet.microsoft.com/ko-kr/library/jj150580(v=exchg.150).aspx>
데이터베이스(.edb) 파일
Exchange 데이터베이스(.edb) 파일은 사서함 데이터의 리포지토리입니다. 데이터베이스 파일은 ESE에서 직접 액세스하며 빠른 액세스를 위한 B+트리 구조를 가지므로 사용자가 4회의 I/O(입/출력) 주기 이내에 모든 데이터 페이지에 액세스할 수 있습니다. Exchange 데이터베이스는 인덱싱 및 보기를 보관하여 주 트리와 함께 사용할 수 있는 보조 트리와 여러 개의 B+트리로 구성됩니다.
| 참고: |
| Exchange 2007에서는 Exchange Server 2003에서 사용되었던 스트림(.stm) 파일 형식을 사용하지 않습니다. 이전에는 .edb와 .stm 파일 간에 분리되었던 데이터가 이제는 .edb 파일에만 저장됩니다. |
출처: <http://technet.microsoft.com/ko-kr/library/bb331964(v=exchg.80).aspx>
로그(.log) 파일
Exchange 2007에서는 메시지 작성 또는 수정 등의 작업이 해당 데이터베이스의 저장소 그룹에 대한 로그(.log) 파일에 기록됩니다. 그리고 커밋된 트랜잭션은 이후에 데이터베이스 자체(.edb 파일)에 기록됩니다. 이 방법을 사용하면 완료된 트랜잭션 및 진행 중인 트랜잭션이 모두 기록되므로 서비스가 중단될 때도 데이터 무결성을 유지할 수 있습니다. 저장소 그룹의 데이터베이스는 E0000000001.log, E0000000002.log 등 연속되는 숫자로 명명된 단일 트랜잭션 로그 집합을 공유합니다.
검사점(.chk) 파일
검사점(.chk) 파일에는 트랜잭션이 하드 디스크의 데이터베이스에 저장된 시점을 나타내는 정보가 저장됩니다. Exchange 2007에서는 검사점 파일을 사용하여 서비스 중단 시 복구를 수행할 때 ESE 인스턴스가 기록되지 않은 다음 트랜잭션에서부터 로그 파일을 불일치하는 데이터베이스로 자동 재생되도록 합니다.
트랜잭션 로깅에 대한 자세한 내용은 트랜잭션 로깅 이해를 참조하십시오.
출처: <http://technet.microsoft.com/ko-kr/library/bb331964(v=exchg.80).aspx>
큐 데이터베이스의 위치 변경
큐 는 다음 처리 단계를 기다리는 메시지의 임시 보관 위치입니다. 각각의 큐는 전송 서버가 특정 순서로 처리하는 메시지의 논리적 집합을 나타냅니다.
Microsoft Exchange Server 2013에서는 이전 버전의 Exchange와 같이 큐 메시지 저장소로 ESE(Extensible Storage Engine) 데이터베이스를 사용합니다. 여러 다양한 큐가 모두 단일 ESE 데이터베이스에 저장됩니다. 큐는 사서함 서버 또는 Edge 전송 서버에만 있습니다.
큐 데이터베이스 및 큐 데이터베이스 트랜잭션 로그의 위치는 %ExchangeInstallPath%Bin\EdgeTransport.exe.config XML 응용 프로그램 구성 파일의 키를 통해 제어합니다. 이 파일은 Microsoft Exchange Transport Service와 연결되어 있습니다. 다음 표에서는 각 키에 대해 더 자세히 설명합니다.
| 키 | 설명 |
| QueueDatabasePath | 이 키는 큐 데이터베이스 파일의 위치를 지정합니다. 해당 파일은 다음과 같습니다.
기본 위치는 %ExchangeInstallPath%TransportRoles\data\Queue입니다. |
| QueueDatabaseLoggingPath | 이 키는 큐 데이터베이스 트랜잭션 로그 파일의 위치를 지정합니다. 해당 파일은 다음과 같습니다.
Temp.edb 는 Microsoft Exchange Transport Service가 시작될 때 큐 데이터베이스 스키마를 확인하는 데 사용됩니다. Temp.edb는 트랜잭션 로그 파일이 아니지만 트랜잭션 로그 파일과 같은 위치에 저장됩니다. 기본 위치는 %ExchangeInstallPath%TransportRoles\data\Queue입니다. |
출처: <http://technet.microsoft.com/ko-kr/library/bb125177(v=exchg.150).aspx>
Exchange 저장소의 파일 구조
Exchange 저장소는 데이터베이스 등의 논리 구성 요소를 통해 관리합니다. 그러나 Exchange 2010에서는 Exchange 데이터베이스 파일(.edb), 트랜잭션 로그 파일(.log) 및 검사점 파일(.chk)과 같은 특수한 데이터 파일 집합에 데이터가 저장됩니다. 데이터를 백업 또는 복원할 때가 아니면 이러한 파일을 직접 사용하는 경우는 거의 없습니다. 다음 표에서는 이러한 각 파일에 대해 자세히 설명합니다.
Exchange 저장소의 파일 구조
| 데이터 파일 | 설명 |
| Exchange 데이터베이스(.edb) | 이 파일은 사서함 데이터용 리포지토리입니다. 이 파일은 ESE(Extensible Storage Engine)에서 직접 엑세스할 수 있으며, 빠른 액세스를 위한 B-트리 구조가 있습니다. 이 파일을 통해 사용자는 Microsoft Exchange Server 2007에 비해 4배나 증가한 단일 I/O(입출력) 주기 내에서 임의 데이터 페이지에 액세스할 수 있습니다. Exchange 데이터베이스는 여러 개의 B-트리로 구성되며 인덱싱 및 보기를 보관하여 주 트리와 함께 작동하는 보조 트리가 있습니다. |
| 트랜잭션 로그(.log) | 이 파일은 메시지 생성 또는 수정과 같은 데이터베이스 작업용 리포지토리입니다. 커밋된 작업은 이후에 데이터베이스 자체(.edb 파일)에 기록됩니다. 이 방법은 서비스가 중단될 경우 데이터 무결성을 유지하기 위해 완료된 트랜잭션과 완료되지 않은 트랜잭션이 모두 로깅되도록 합니다. 각 데이터베이스에 고유한 트랜잭션 로그 집합이 있습니다. |
| 검사점(.chk) | 이 파일은 작업이 성공적으로 하드 디스크의 데이터베이스에 저장된 경우를 나타내는 데이터용 리포지토리입니다. Exchange 2010에서는 .chk 파일을 사용하여 ESE 인스턴스가 서비스 중단 상태를 복구할 때 자동으로 로그 파일을 일관성 없는 데이터베이스로 재생할 수 있도록 함으로써 기록되지 않은 다음 트랜잭션부터 시작되게 합니다. .chk 파일은 .log 파일과 동일한 로그 위치에 저장됩니다. |
출처: <http://technet.microsoft.com/ko-kr/library/bb331958(v=exchg.141).aspx>
트랜잭션 로깅 이해
Exchange 트랜잭션 로깅은 Exchange 데이터베이스가 갑자기 중지된 경우에 해당 데이터베이스를 일관성 있는 상태로 안정적으로 복원하도록 설계된 강력한 ESE 복구 메커니즘입니다. 온라인 백업을 복원하는 경우 로깅 메커니즘도 사용됩니다. 이 섹션에서는 순환 로깅에 대한 간략한 설명을 포함하여 Exchange 2010 트랜잭션 로깅에 대해 자세히 설명합니다.
Exchange 트랜잭션 로깅
Exchange 데이터베이스 파일을 변경하기 전에 Exchange에서는 트랜잭션 로그 파일에 변경 내용을 기록합니다. 변경 내용이 안전하게 로깅된 후에는 데이터베이스 파일에 기록될 수 있습니다. 일반적으로 이러한 변경 내용은 트랜잭션 로그에 안전하게 기록된 후 데이터베이스 파일에 기록되기 전에 최종 사용자가 사용할 수 있습니다.
Exchange에서는 수십 GB의 데이터베이스 페이지 캐싱을 효율적으로 관리하는, 고성능을 발휘하도록 조정된 정교한 내부 메모리 관리 시스템을 사용합니다. 정상적인 작동 중에 데이터베이스 파일에 변경 내용을 실제로 쓰는 작업은 우선 순위가 낮습니다.
데이터베이스가 갑자기 중지되는 경우 메모리 캐시가 손상되었다는 이유만으로 캐시된 변경 내용이 손실되지는 않습니다. 데이터베이스가 다시 시작되면 Exchange에서는 로그 파일을 검색한 다음 데이터베이스 파일에 아직 기록되지 않은 변경 내용을 재구성하고 적용합니다. 이 프로세스를 로그 파일 재생이라고 합니다. 데이터베이스는 Exchange에서 로그 파일의 작업이 데이터베이스에 이미 적용되었는지, 데이터베이스에 적용되어야 하는지 또는 데이터베이스에 속하지 않는지 확인할 수 있도록 구성됩니다.
Exchange는 하나의 큰 파일에 모든 로그 정보를 쓰지 않고 각 파일 크기가 정확히 1MB 또는 1,024KB인 일련의 로그 파일을 사용합니다. 한 로그 파일이 꽉 차면 Exchange에서는 해당 파일을 닫고 순번을 붙여 이름을 바꿉니다. 채워진 첫 번째 로그 이름은 Enn00000001.log로 끝납니다. nn은 기본 이름 또는 로그 접두사인 2자리 숫자를 나타냅니다.
각 데이터베이스에 대한 로그 파일은 번호가 매겨진 접두사(예: E00, E01, E02 또는 E03)가 붙은 이름으로 구분됩니다. 현재 데이터베이스에 대해 열려 있는 로그 파일의 이름은 Enn.log입니다. 채운 후 닫을 때까지 시퀀스 번호가 지정되지 않습니다.
검사점 파일(Enn.chk)은 Exchange에서 로깅된 정보가 데이터베이스 파일에 어느 정도 기록되었는지 추적합니다. 각 로그 스트림에 대해 하나의 검사점 파일이 있고 각 데이터베이스에 대해 별도의 로그 스트림이 있습니다.
로그 파일은 16진수로 번호가 매겨집니다. 즉, E0000000009.log 다음의 로그 파일은 E0000000010.log가 아니라 E000000000A.log입니다. 공학용 모드로 설정된 Windows 계산기(Calc.exe) 응용 프로그램을 사용하여 로그 파일 시퀀스 번호를 10진수로 변환할 수 있습니다. 이렇게 하려면 Calc.exe를 실행한 다음 보기 메뉴에서 공학용 을 클릭합니다.
특 정 로그 파일의 10진수로 된 시퀀스 번호를 보려면 Exchange Server 데이터베이스 유틸리티(Eseutil.exe) 도구를 사용하여 해당 헤더를 검토하면 됩니다. 각 로그 파일의 처음 4KB 페이지에는 로그 파일과 해당 로그 파일이 속하는 데이터베이스를 설명하고 식별하는 헤더 정보가 있습니다. Eseutil /ml [log file name] 명령을 실행하면 헤더 정보가 표시됩니다.
헤더를 표시할 때 잘못된 스위치를 사용하면(예: 데이터베이스 헤더에 /mh 대신 /ml 사용) 오류가 표시되거나 올바르지 않은 헤더 정보가 표시됩니다.
데 이터베이스가 탑재되는 동안에는 해당 데이터베이스의 헤더를 볼 수 없습니다. 데이터베이스가 탑재되는 동안에는 현재 로그 파일(Enn.log)의 헤더도 볼 수 없습니다. Exchange에서는 파일을 사용 중인 데이터베이스가 하나라도 있는 경우 현재 로그 파일을 열어 둡니다. 그러나 데이터베이스가 탑재되는 동안 검사점 파일 헤더를 볼 수 있습니다. Exchange에서는 30초 간격으로 검사점 파일을 업데이트합니다. 업데이트가 진행 중인 경우를 제외하고 해당 헤더를 볼 수 있습니다.
Exchange 파일 헤더를 이해하는 것이 Exchange 관리자에게 유용합니다. 파일 헤더를 이해하면 함께 속해 있는 데이터베이스 및 로그 파일과 성공적인 복구에 필요한 파일을 확인할 수 있습니다.
다음 로그 파일 헤더 예제에서 처음 네 개의 행을 확인하십시오.
Base name: e00
Log file: e00.log
lGeneration: 11 (0xB)
Checkpoint: (0xB,7DC,6F)
이러한 로그 파일 헤더 행은 로그 파일 이름에 시퀀스 번호가 없으므로 해당 파일이 현재 로그 파일임을 보여 줍니다. lGeneration 행은 로그 파일이 채워진 후 닫힐 때 해당 로그 파일의 시퀀스 번호가 10진수 11에 해당하는 B가 된다는 것을 보여 줍니다. 기본 이름은 e00이므로 최종 로그 파일 이름은 E000000000B.log가 됩니다.
앞의 헤더 예에 나오는 Checkpoint 값은 실제로 로그 파일 헤더에서 읽지 않았지만 읽은 것처럼 표시됩니다. Eseutil.exe는 Enn.chk에서 직접 Checkpoint 값을 읽으므로 검사점 파일의 위치를 알기 위해 별도의 명령을 입력할 필요가 없습니다. 검사점 파일이 손상되면 Checkpoint 값은 NOT AVAILABLE을 읽습니다. 이 경우 검사점은 현재 로그 파일(0xB)에 있으며 숫자 7DC 및 6F는 로그 파일에서의 검사점 위치를 나타냅니다. 실제로는 이 정보가 거의 필요하지 않습니다.
검 사점 파일이 손상되어도 Exchange에서는 로그 파일을 복구하고 재생할 수 있습니다. 그러나 이를 위해 Exchange는 검사점 로그에서가 아니라 사용 가능한 가장 오래된 파일에서 로그 파일 검색을 시작합니다. Exchange에서는 데이터베이스에 이미 적용된 데이터는 건너뛰고, 적용되어야 하는 데이터가 발생할 때까지 로그를 사용하여 순차적으로 작업을 수행합니다.
일 반적으로 Exchange에서 데이터베이스에 이미 적용된 로그 파일을 검색하는 데는 1~2초 정도만 걸립니다. 데이터베이스에 기록해야 하는 로그 파일의 작업이 있는 경우 해당 작업을 적용하는 데 10초에서 몇 분 정도 걸릴 수 있습니다. 평균적으로 30초 이내에 로그 파일의 내용을 데이터베이스에 쓸 수 있습니다.
Exchange 데이터베이스가 정상적으로 종료되면 처리되지 않은 데이터는 모두 데이터베이스 파일에 기록됩니다. 정상적인 종료 후 데이터베이스 파일 집합은 일관성 있는 상태에 있다고 간주되므로 Exchange에서는 해당 데이터베이스 파일 집합을 로그 스트림에서 분리합니다. 이는 현재 데이터베이스 파일이 자체 포함된 상태(최신 상태)임을 의미합니다. 트랜잭션 로그는 데이터베이스 파일을 시작하는 데 필요하지 않습니다.
Eseutil /mh 명령을 실행하고 파일 헤더를 검토하여 데이터베이스가 완전히 종료되었는지 확인할 수 있습니다.
모 든 데이터베이스가 연결이 끊어지고 완전한 종료 상태가 되면 데이터베이스에 영향을 주지 않고 모든 로그 파일을 안전하게 삭제할 수 있습니다. 그런 다음 모든 로그 파일을 삭제하면 Exchange에서 Enn00000001.log로 시작하는 새 로그 시퀀스를 생성합니다. 데이터베이스 파일을 기존 로그 파일이 있는 다른 서버로 이동할 수도 있으며 데이터베이스가 자동으로 다른 로그 스트림에 연결됩니다.
| 참고: |
| 모든 데이터베이스가 종료된 후에 로그 파일을 삭제할 수 있지만 이렇게 하면 이전 백업의 복원 및 롤포워드에 영향을 줄 수 있습니다. 현재 데이터베이스에는 더 이상 기존 로그 파일이 필요하지 않지만 이전 데이터베이스를 복원해야 할 경우에는 기존 로그 파일이 필요할 수도 있습니다. |
데이터베이스가 부적절한 종료 상태일 때 데이터베이스를 다시 탑재하려면 검사점 앞에서부터 기존의 모든 트랜잭션 로그가 있어야 합니다. 이러한 로그를 사용할 수 없으면 Eseutil /p 명령으로 데이터베이스를 복구하여 일관성 있고 시작할 수 있는 상태로 만들어야 합니다.
| 주의: |
| 데이터베이스를 복구해야 할 경우 일부 데이터가 손실됩니다. 일반적으로 최소한의 데이터 손실이 발생하지만 문제가 될 수도 있습니다. 데이터베이스에서 Eseutil /p 를 실행한 후에 Eseutil/d 를 실행하여 데이터베이스 조각 모음을 수행해야 합니다. 이 작업은 모든 데이터베이스 인덱스 및 공간 트리를 삭제한 후 다시 작성합니다. |
트랜잭션 로깅은 예기치 않은 데이터베이스 중지가 발생한 경우 Exchange에서 안전하게 복구할 수 있도록 하는 것 외에도 온라인 백업을 만들고 복원하는 데 반드시 필요합니다. 온라인 백업을 만들고 복원하는 방법에 대한 자세한 내용은 백업, 복원 및 재해 복구 이해를 참조하십시오.
순환 로깅
순 환 로깅을 사용하도록 설정하여 디스크 공간을 절약하도록 Exchange를 구성할 수 있습니다. 순환 로깅을 사용하면 Exchange는 트랜잭션 로그 파일 내의 데이터가 데이터베이스로 커밋된 후에 트랜잭션 로그 파일을 덮어씁니다. 그러나 순환 로깅을 사용하면 마지막 전체 백업을 수행할 때까지만 데이터를 복구할 수 있습니다. 예를 들어, 백업을 만들지 않는 Exchange 고유 데이터 보호를 사용하는 경우 순환 로깅을 사용하도록 설정할 수 있습니다. 로그가 너무 많이 쌓이지 않게 하려면 순환 로깅을 사용하도록 설정해야 합니다.
Exchange 2010에서 사용되는 표준 트랜잭션 로깅에서는 각 데이터베이스 트랜잭션이 로그 파일에 기록된 다음 데이터베이스에 기록됩니다. 로그 파일이 1MB에 도달하면 이름이 바뀌고 새 로그 파일이 생성됩니다. 시간이 경과하면서 로그 파일 집합이 만들어집니다. Exchange가 예기치 않게 중지되면 이러한 로그 파일의 데이터를 데이터베이스로 다시 재생하여 트랜잭션을 복구할 수 있습니다. 순환 로깅은 첫 번째 로그 파일에 포함된 데이터가 데이터베이스에 기록된 후 그 로그 파일을 덮어쓰고 다시 사용합니다.
Exchange 2010에서 순환 로깅은 기본적으로 사용되지 않습니다. 순환 로깅을 사용하여 드라이브 저장 공간 크기를 줄입니다. 그러나 완전한 트랜잭션 로그 파일 집합이 없으면 마지막 전체 백업 이후의 최신 데이터를 복구할 수 없습니다. 정상적인 프로덕션 환경에서는 순환 로깅이 권장되지 않습니다.
순환 로깅을 사용하거나 사용하지 않도록 설정하는 방법에 대한 자세한 내용은 사서함 데이터베이스 속성 구성을 참조하십시오.
출처: <http://technet.microsoft.com/ko-kr/library/bb331958(v=exchg.141).aspx>
지원되는 저장소 구성에 대한 모범 사례
이 섹션에서는 지원되는 디스크 및 배열 컨트롤러 구성에 대한 모범 사례 정보를 제공합니다.
RAID(Redundant Array of Independent Disks)는 여러 디스크 간에 데이터를 스트라이프하여 개별 디스크의 성능 특성을 향상시킬 뿐 아니라 개별 디스크 오류로부터 보호하는 데 종종 사용됩니다. Exchange 2013의 고가용성이 향상되어 RAID는 Exchange 2013 저장소 설계에 있어 필수 구성 요소가 아닙니다. 그러나 RAID는 여전히 독립 실행형 서버와 저장소 내결함성이 필요한 솔루션에 대한 Exchange 2013 저장소 설계의 필수 구성 요소입니다.
운영 체제, 시스템 또는 페이지 파일 볼륨
운영 체제, 시스템 또는 페이지 파일 볼륨에 대해 권장되는 구성은 RAID 기술을 사용하여 이 데이터 형식을 보호하는 것입니다. 권장되는 RAID 구성은 RAID-1 또는 RAID-1/0이지만 모든 RAID 유형이 지원됩니다.
구분된 사서함 데이터베이스 및 로그 볼륨
독 립 실행형 사서함 서버 역할 아키텍처를 배포하는 경우 사서함 데이터베이스 및 로그 볼륨에 RAID 기술이 필요합니다. 사서함 볼륨에 권장되는 RAID 구성은 RAID-1/0(특히 5.4K 또는 7.2K 디스크를 사용 중인 경우)이지만 모든 RAID 유형이 지원됩니다. 로그 볼륨의 경우 RAID-1 또는 RAID-1/0이 권장되는 RAID 구성입니다.
운영 체제, 페이지 파일 또는 Exchange 데이터 볼륨에 RAID-5 또는 RAID-6 구성을 사용하는 경우 다음 사항에 유의합니다.
- RAID-5 구성(RAID-50, RAID-51 등의 변형 포함)에서는 배열 그룹당 7개 이하의 디스크가 있어야 하며 배열 컨트롤러의 높은 우선 순위 스크러빙 및 영역 검사를 사용하도록 설정해야 합니다.
- RAID-6 구성에서는 배열 컨트롤러의 높은 우선 순위 스크러빙 및 영역 검사를 사용하도록 설정해야 합니다.
고가용성 데이터베이스 복사본이 세 개 이상 있는 고가용성 아키텍처에서 JBOD가 지원되기는 하지만 로그 볼륨과 사서함 데이터베이스 볼륨이 분리되어 있기 때문에 JBOD는 사용하지 않는 것이 좋습니다.
사서함 데이터베이스 및 로그 볼륨 배치
독립 실행형 아키텍처에서는 사서함 데이터베이스 및 로그 볼륨 배치를 사용하지 않는 것이 좋습니다. 고가용성 아키텍처에서는 이 시나리오에 대한 두 가지 가능성이 있습니다.
- 볼륨당 단일 데이터베이스
- 볼륨당 여러 개의 데이터베이스
볼륨당 단일 데이터베이스
Exchange 관점에서 JBOD는 데이터베이스와 단일 디스크에 저장된 자체 관련 로그를 모두 가지고 있음을 의미합니다. JBOD에서 배포하려면 최소한 세 개의 고가용성 데이터베이스 복사본을 배포해야 합니다. 디스크에 오류가 발생하는 경우 해당 디스크에 있는 데이터베이스 복사본이 손실되기 때문에 단일 디스크 사용은 단일 실패 지점에 해당합니다. 최소한 세 개의 데이터베이스 복사본이 있으면 하나의 복사본(또는 디스크 하나)에 오류가 생기는 경우 두 개의 추가 복사본이 있으므로 내결함성이 보장됩니다. 하지만 세 개의 고가용성 데이터베이스 복사본 배치 및 지연된 데이터베이스 복사본 사용은 저장소 디자인에 영향을 줄 수 있습니다. 다음 표에서는 RAID 또는 JBOD 고려 사항에 대한 지침이 나와 있습니다.
RAID 또는 JBOD 고려 사항
| 데이터 센터 서버 | 2개의 고가용성 복사본(합계) | 3개의 고가용성 복사본(합계) | 데이터 센터당 2~3개의 고가용성 복사본 | 1개의 지연된 복사본 | 데이터 센터당 2개 이상의 지연된 복사본 |
| 기본 데이터 센터 서버 | RAID | RAID 또는 JBOD(2개의 복사본) | RAID 또는 JBOD | RAID | RAID 또는 JBOD |
| 보조 데이터 센터 서버 | RAID | RAID(1개의 복사본) | RAID 또는 JBOD | RAID | RAID 또는 JBOD |
기 본 데이터 센터 서버가 포함된 JBOD에서 배포하려면 DAG 내에 고가용성 데이터베이스 복사본이 세 개 이상 필요합니다. 고가용성 데이터베이스 복사본을 호스팅하는 동일한 서버에서 지연된 복사본을 혼합하는 경우(예: 지연된 전용 데이터베이스 복사본 서버 사용 안 함) 지연된 데이터베이스 복사본이 두 개 이상 필요합니다.
JBOD를 사용하기 위한 보조 데이터 센터 서버의 경우 보조 데이터 센터에 고가용성 데이터베이스 복사본이 두 개 이상 있어야 합니다. 보조 데이터 센터의 복사본이 손실되어도 보조 데이터 센터가 활성화되는 경우 WAN에서 다시 시드를 필요로 하거나 단일 실패 지점을 가지게 되지 않습니다. 고가용성 데이터베이스 복사본을 호스팅하는 동일한 서버에서 지연된 데이터베이스 복사본을 혼합하는 경우(예: 지연된 전용 데이터베이스 복사본 서버 사용 안 함) 지연된 데이터베이스 복사본이 두 개 이상 필요합니다.
지연된 전용 데이터베이스 복사본 서버의 경우 JBOD를 사용하려면 데이터 센터 내에 지연된 데이터베이스 복사본이 두 개 이상 있어야 합니다. 그렇지 않으면 디스크 손실로 인해 지연된 데이터베이스 복사본 손실 및 보호 메커니즘 손실이 발생하게 됩니다.
볼륨당 여러 개의 데이터베이스
볼 륨당 여러 개의 데이터베이스는 단일 디스크에 활성/수동 복사본(지연된 복사본 포함)이 모두 있을 수 있는 Exchange 2013에서 사용 가능한 새로운 JBOD 시나리오로, 디스크 사용률을 높여줍니다. 하지만 이 방법으로 지연된 복사본을 배포하려면 지연된 복사본 로그 파일 자동 재생을 사용하도록 설정해야 합니다. 다음 표에서는 볼륨당 여러 개의 데이터베이스에 대한 JBOD 고려 사항과 관련 지침이 나와 있습니다.
JBOD 고려 사항
| 데이터 센터 서버 | 3개 이상의 복사본(전체) | 데이터 센터당 2개 이상의 복사본 |
| 기본 데이터 센터 서버 | JBOD | JBOD |
| 보조 데이터 센터 서버 | 해당 없음 | JBOD |
다음 표에서는 Exchange 2013의 저장소 배열 구성에 대한 지침을 제공합니다.
Exchange 2013 사서함 서버 역할에 지원되는 RAID 유형
| RAID 유형 | 설명 | 지원됨 또는 모범 사례 |
| 디스크 배열 RAID 스트라이프 크기(KB) | 스트라이프 크기는 RAID 세트 내에서의 데이터 분포의 디스크당 단위입니다. 스트라이프 크기는 블록 크기 라고도 합니다. | 모범 사례: 256KB 이상. 저장소 공급업체의 모범 사례에 따르십시오. |
| 저장소 배열 캐시 설정 | 캐시 설정은 배터리가 지원되는 캐싱 배열 컨트롤러에서 제공합니다. | 모범 사례: 쓰기 캐시 75% 및 읽기 캐시 25%(배터리가 지원되는 캐시). 저장소 공급업체의 모범 사례에 따르십시오. 이 지침은 JBOD 고려 사항에도 적용됩니다. |
| 실제 디스크 쓰기 캐싱 | 캐시에 대한 설정은 각각의 개별 디스크에 있습니다. | 지원: UPS 없이 사용할 경우 실제 디스크 쓰기 캐싱을 사용하지 않도록 설정해야 합니다. |
다음 표에서는 데이터베이스 및 로그 파일 선택에 대한 지침을 제공합니다.
Exchange 2013 사서함 서버 역할에 대한 데이터베이스 및 로그 파일 선택
| 데이터베이스 및 로그 파일 옵션 | 설명 | 독립 실행형: 지원됨 또는 모범 사례 | 고가용성: 지원됨 또는 모범 사례 |
| 파일 배치: 데이터베이스/로그 격리 | 데이터베이스/로그 격리는 동일한 사서함 데이터베이스의 데이터베이스 파일과 로그를 여러 개의 실제 디스크에서 지원하는 여러 볼륨에 배치하는 것을 의미합니다. | 모범 사례: 복구 기능을 위해 동일한 데이터베이스의 데이터베이스 파일(.edb)과 로그를 여러 개의 실제 디스크가 지원하는 여러 볼륨으로 이동합니다. | 지원: 로그 및 데이터베이스의 격리는 필요하지 않습니다. |
| 파일 배치: 데이터베이스 파일/볼륨 | 데이터베이스 파일/볼륨은 디스크 볼륨 내에서 또는 디스크 볼륨 간에 데이터베이스 파일을 분산하는 방법을 나타냅니다. | 모범 사례: 백업 방법을 기반으로 합니다. | 지원: JBOD를 사용할 때 데이터베이스와 로그 파일용으로 별도의 디렉터리가 포함된 볼륨 하나를 만듭니다. |
| 파일 배치: 로그 스트림/볼륨 | 로그 스트림/볼륨은 디스크 볼륨 내에서 또는 디스크 볼륨 간에 데이터베이스 로그 파일을 분산하는 방법을 나타냅니다. | 모범 사례: 백업 방법을 기반으로 합니다. | 지원: JBOD를 사용할 때 데이터베이스와 로그 파일용으로 별도의 디렉터리가 포함된 볼륨 하나를 만듭니다.모범 사례: JBOD를 사용할 때 볼륨당 여러 데이터베이스를 활용합니다. |
| 데이터베이스 크기 | 데이터베이스 크기는 디스크 데이터베이스(.edb) 파일 크기를 의미합니다. | 지원: 약 16테라바이트.모범 사례:
|
지원: 약 16테라바이트.모범 사례:
|
| 로그 자르기 방법 | 로그 자르기 방법은 오래된 데이터베이스 로그 파일의 자르기 및 삭제 프로세스입니다. 다음 두 가지 메커니즘이 있습니다.
|
모범 사례:
|
모범 사례:
|
다음 표에서는 Windows 디스크 유형에 대한 지침을 제공합니다.
Exchange 2013 사서함 서버 역할에 대한 Windows 디스크 유형
| Windows 디스크 유형 | 설명 | 독립 실행형: 지원됨 또는 모범 사례 | 고가용성: 지원됨 또는 모범 사례 |
| 기본 디스크 | 기본 저장소용으로 초기화된 디스크를 기본 디스크라고 합니다. 기본 디스크에는 주 파티션, 확장 파티션, 논리 드라이브 등의 기본 볼륨이 포함됩니다. | 지원됨.모범 사례: 기본 디스크를 사용합니다. | 지원됨.모범 사례: 기본 디스크를 사용합니다. |
| 동적 디스크 | 동적 저장소용으로 초기화된 디스크를 동적 디스크라고 합니다. 동적 디스크에는 단순 볼륨, 스팬 볼륨, 스트라이프 볼륨, 미러 볼륨, RAID-5 볼륨 등의 동적 볼륨이 포함됩니다. | 지원됨. | 지원됨. |
다음 표에서는 볼륨 구성에 대한 지침을 제공합니다.
Exchange 2013 사서함 서버 역할에 대한 볼륨 구성
| 볼륨 구성 | 설명 | 독립 실행형: 지원됨 또는 모범 사례 | 고가용성: 지원됨 또는 모범 사례 |
| GPT(GUID 파티션 테이블) | GPT는 이전 MBR(마스터 부트 레코드) 파티션 구성표에서 확장되는 디스크 아키텍처입니다. NTFS로 포맷된 파티션의 최대 크기는 256테라바이트입니다. | 지원됨.모범 사례: GPT 파티션을 사용합니다. | 지원됨.모범 사례: GPT 파티션을 사용합니다. |
| MBR | MBR 즉, 파티션 섹터는 하드 디스크와 같이 분할된 데이터 저장소 장치의 첫 번째 섹터(LBA 섹터 0)인 512바이트의 부팅 섹터입니다. NTFS로 포맷된 파티션의 최대 크기는 2테라바이트입니다. | 지원됨. | 지원됨. |
| 파티션 맞춤 | 파티션 맞춤은 최적의 성능을 위해 섹터 경계에서 파티션을 맞추는 것을 나타냅니다. | 지원: Windows Server 2008 R2 및 Windows Server 2012 기본값은 1MB입니다. | 지원: Windows Server 2008 R2 및 Windows Server 2012 기본값은 1MB입니다. |
| 볼륨 경로 | 볼륨 경로는 볼륨에 액세스하는 방법을 나타냅니다. | 지원: 드라이브 문자 또는 탑재 지점.모범 사례: 탑재 지점 호스트 볼륨은 RAID를 사용하도록 설정되어 있어야 합니다. | 지원: 드라이브 문자 또는 탑재 지점.모범 사례: 탑재 지점 호스트 볼륨은 RAID를 사용하도록 설정되어 있어야 합니다. |
| 파일 시스템 | 파일 시스템은 컴퓨터 파일과 파일에 포함된 데이터를 찾아 액세스하기 쉽게 저장 및 구성하는 방법을 나타냅니다. | 지원: NTFS 및 ReFS | 지원: NTFS 및 ReFS |
| NTFS 조각 모음 | NTFS 조각 모음은 Windows 파일 시스템에 있는 조각 양을 줄이는 프로세스입니다. 이 프로세스는 디스크의 콘텐츠를 물리적으로 구성하여 각 파일 조각을 가까이 인접하여 저장합니다. | 지원됨.모범 사례: 필요하지 않으며 권장되지 않음. Windows Server 2012에서는 자동 디스크 최적화 및 조각 모음 기능도 사용하지 않도록 설정하는 것이 좋습니다. | 지원됨.모범 사례: 필요하지 않으며 권장되지 않음. Windows Server 2012에서는 자동 디스크 최적화 및 조각 모음 기능도 사용하지 않도록 설정하는 것이 좋습니다. |
| NTFS 할당 단위 크기 | NTFS 할당 단위 크기는 파일 저장을 위해 할당할 수 있는 최소 디스크 공간을 나타냅니다. | 지원: 모든 할당 단위 크기모범 사례: .edb 및 로그 파일 볼륨 모두에 대해 64KB | 지원: 모든 할당 단위 크기모범 사례: .edb 및 로그 파일 볼륨 모두에 대해 64KB |
| NTFS 압축 | NTFS 압축은 하드 디스크에 저장된 파일의 실제 크기를 줄이는 프로세스입니다. | 지원: Exchange 데이터베이스 또는 로그 파일에 대해서는 지원되지 않음. | 지원: Exchange 데이터베이스 또는 로그 파일에 대해서는 지원되지 않음. |
| NTFS EFS(파일 시스템 암호화) | EFS 를 통해 사용자는 개별 파일, 폴더 또는 전체 데이터 드라이브를 암호화할 수 있습니다. EFS는 업계 표준 알고리즘 및 공개 키 암호화를 통해 강력한 암호화를 제공하기 때문에 공격자가 시스템 보안을 통과하는 경우에도 암호화된 파일은 기밀로 유지됩니다. | 지원: Exchange 데이터베이스 또는 로그 파일에 대해서는 지원되지 않음. | Exchange 데이터베이스 또는 로그 파일에 대해서는 지원되지 않음. |
| Windows BitLocker(볼륨 암호화) | Windows BitLocker는 Windows Server 2008의 데이터 보호 기능입니다. BitLocker는 분실하거나 도난 당한 컴퓨터에 들어 있는 데이터가 도난 당하거나 노출되지 않도록 보호하며, 컴퓨터를 폐기할 때 데이터를 보다 안전하게 삭제할 수 있도록 합니다. | 지원: 모든 Exchange 데이터베이스 및로그파일 . | 지 원: 모든 Exchange 데이터베이스 및 로그 파일. Windows 장애 조치(failover) 클러스터를 사용하려면 Windows Server 2008 R2 또는 Windows Server 2008 R2 SP1과 다음 핫픽스가 있어야 합니다. 컴퓨터가 장애 조치(failover) 클러스터 노드인 경우 Windows Server 2008 R2의 디스크 볼륨에서 BitLocker를 사용하도록 설정할 수 없다. Bitlocker가 사용하도록 설정된 Exchange 볼륨은 이전 버전의 Windows를 실행하는 Windows 장애 조치(failover) 클러스터에서 지원되지 않습니다.Windows 7 BitLocker 암호화에 대한 자세한 내용은 Windows 7에서의 BitLocker 드라이브 암호화: 질문과 대답을 참조하십시오. |
| SMB(서버 메시지 블록) 3.0 | SMB(서 버 메시지 블록) 프로토콜은 컴퓨터의 응용 프로그램이 원격 서버의 파일과 리소스에 액세스할 수 있도록 하는 네트워크 파일 공유 프로토콜(TCP/IP 또는 기타 네트워크 프로토콜 위에 있음)입니다. 또한 SMB 프로토콜은 응용 프로그램이 SMB 클라이언트 요청을 받도록 설정된 모든 서버 프로그램과 통신할 수 있도록 합니다. Windows Server 2012에는 다음 기능이 포함된 SMB 프로토콜의 새로운 3.0 버전이 도입되었습니다.
|
제한된 지원. 지원되는 시나리오는 디스크가 SMB 3.0 공유 위치의 VHD에 호스트되는 하드웨어 가상화 배포입니다. 이러한 VHD는 하이퍼바이저를 통해 호스트에 제공됩니다. 자세한 내용은 Exchange 2013 가상화를 참조하십시오. | 제한된 지원. 지원되는 시나리오는 디스크가 SMB 3.0 공유 위치의 VHD에 호스트되는 하드웨어 가상화 배포입니다. 이러한 VHD는 하이퍼바이저를 통해 호스트에 제공됩니다. 자세한 내용은 Exchange 2013 가상화를 참조하십시오. |
| 저장소 공간 | 저 장소 공간은 Windows Server 2012용 가상화 기능을 제공하는 새로운 저장소 솔루션입니다. 저장소 공간을 통해 실제 디스크를 저장소 풀(디스크만 추가하면 쉽게 확장 가능)로 구성할 수 있습니다. USB, SATA 또는 SAS를 통해 이러한 디스크를 연결할 수 있습니다. 또한 저장소 공간은 씬 프로비저닝 등의 강력한 관련 기능과 기본 실제 미디어 오류 복원 기능을 포함하며 실제 디스크처럼 작동하는 가상 디스크(공간)도 활용합니다. 저장소 공간에 대한 자세한 내용은 저장소 공간 개요를 참조하십시오. | 지원됨. 이 항목에서 설명하는 실제 디스크 유형과 동일한 제한이 적용됩니다. | 지원됨. 이 항목에서 설명하는 실제 디스크 유형과 동일한 제한이 적용됩니다. |
| ReFS(복원 파일 시스템) | ReFS 는 Windows Server 2012용으로 새롭게 제작된 파일 시스템이며 NTFS를 기반으로 구축되었습니다. ReFS는 NTFS와의 뛰어난 호환성을 유지하는 동시에 고급 데이터 확인 및 자동 수정 기술과 통합된 종단 간 손상 복원 기능을 제공합니다(특히 저장소 공간 기능과 함께 사용하는 경우). ReFS에 대한 자세한 내용은 복원 파일 시스템 개요를 참조하십시오. | 지원됨(다음 핫픽스가 설치된 경우): Windows Server 2012에서 Exchange Server 2013 데이터베이스가 조각남모 범 사례: Exchange 데이터베이스(.edb) 파일 또는 이러한 파일을 호스트하는 볼륨에 대해 데이터 무결성 기능을 사용하지 않도록 설정해야 합니다. 볼륨에 데이터베이스 또는 로그 파일이 포함되어 있지 않은 경우 콘텐츠 인덱스 카탈로그가 포함된 볼륨에 대해 무결성 기능을 사용하도록 설정할 수 있습니다. | 지원됨(다음 핫픽스가 설치된 경우): Windows Server 2012에서 Exchange Server 2013 데이터베이스가 조각남모 범 사례: Exchange 데이터베이스(.edb) 파일 또는 이러한 파일을 호스트하는 볼륨에 대해 데이터 무결성 기능을 사용하지 않도록 설정해야 합니다. 볼륨에 데이터베이스 또는 로그 파일이 포함되어 있지 않은 경우 콘텐츠 인덱스 카탈로그가 포함된 볼륨에 대해 무결성 기능을 사용하도록 설정할 수 있습니다. |
| 데이터 중복 제거 | 데 이터 중복 제거는 Windows Server 2012의 저장소 사용을 최적화하기 위한 새로운 기술로, 데이터의 충실도나 무결성은 그대로 유지하면서 데이터 내 중복을 찾아서 제거하는 방법입니다. 이를 통해 파일을 작은 가변 크기 청크로 분할한 다음 중복 청크를 식별하여 각 청크의 단일 복사본을 유지함으로써 더 적은 공간에 더 많은 데이터를 저장하는 것이 목표입니다. 청크의 중복 복사본은 단일 복사본에 대한 참조로 바뀌고, 청크는 컨테이너 파일에 구성되며, 컨테이너는 보다 나은 공간 최적화를 위해 압축됩니다. | Exchange 데이터베이스 파일에 대해서는 지원되지 않습니다. 참고: 완전히 오프라인 상태인 백업 또는 보관용 Exchange 데이터베이스 파일에 대해 사용할 수 있습니다. | Exchange 데이터베이스 파일에 대해서는 지원되지 않습니다. 참고: 완전히 오프라인 상태인 백업 또는 보관용 Exchange 데이터베이스 파일에 대해 사용할 수 있습니다. |
출처: <http://technet.microsoft.com/ko-kr/library/ee832792(v=exchg.150).aspx>
저장소 아키텍처
다음 표에서는 지원되는 저장소 아키텍처에 대해 설명하고 각 저장소 아키텍처 유형에 대한 모범 사례 지침(해당되는 경우)을 제공합니다.
지원되는 저장소 아키텍처
| 저장소 아키텍처 | 설명 | 모범 사례 |
| DAS(직접 연결 저장소) | DAS 는 서버 또는 워크스테이션에 직접 연결된 디지털 저장소 시스템으로, 사이에 저장소 네트워크가 필요하지 않습니다. 예를 들어, DAS 전송에는 SAS(Serial Attached SCSI) 및 Serial Attached ATA(Advanced Technology Attachment)가 포함됩니다. | 사용할 수 없습니다. |
| SAN(저장 영역 네트워크): iSCSI(Internet Small Computer System Interface) | SAN 은 장치가 운영 체제에 로컬 연결된 것으로 나타나는 방식(예: 블록 저장소)으로 원격 컴퓨터 저장소 장치(예: 디스크 배열 및 테이프 라이브러리)를 서버에 연결하는 아키텍처입니다. iSCSI SAN은 IP 패킷 내에 SCSI 명령을 캡슐화하고 표준 네트워킹 인프라를 저장소 전송으로 사용합니다(예: 이더넷). | Exchange 데이터를 백업하는 실제 디스크를 다른 응용 프로그램과 공유하지 않습니다.전용 저장소 네트워크를 사용합니다.독립 실행형 구성에 대해 여러 네트워크 경로를 사용합니다. |
| SAN: 파이버 채널 | 파이버 채널 SAN은 파이버 채널 패킷 내에 SCSI 명령을 캡슐화하고 일반적으로 특수 파이버 채널 네트워크를 저장소 전송으로 사용합니다. | Exchange 데이터를 백업하는 실제 디스크를 다른 응용 프로그램과 공유하지 않습니다.독립 실행형 구성에 대해 여러 개의 파이버 채널 네트워크 경로를 사용합니다.FC HBA(호스트 버스 어댑터) 조정(예: 큐 크기 및 큐 대상)에 대한 저장소 공급업체의 모범 사례에 따릅니다. |
NAS(Network Attached Storage) 장치는 네트워크에 있는 다른 장치에 파일 기반 데이터 저장소 서비스를 제공하기 위한 목적으로 네트워크에 연결된 자체 포함 컴퓨터입니다. NAS 장치의 운영 체제 및 기타 소프트웨어는 데이터 저장소, 파일 시스템 및 파일 액세스 기능과 이러한 기능의 관리(예: 파일 저장소) 기능을 제공합니다.
Exchange 2013에서는 Exchange 2013 가상화 항목에 나오는 SMB 3.0 시나리오가 아닌 이상 NAS 볼륨의 사용을 지원하지 않으므로 Exchange에서 Exchange 데이터를 저장하는 데 사용하는 모든 저장소는 블록 수준 저장소여야 합니다. 또한 가상화된 환경에서는 하이퍼바이저를 통해 게스트에게 블록 수준 저장소로 제공되는 NAS 저장소는 지원되지 않습니다.
출처: <http://technet.microsoft.com/ko-kr/library/ee832792(v=exchg.150).aspx#Stor>
사서함 데이터를 가져오거나 내보내는 이유
사서함 데이터를 가져오거나 내보내는 이유는 다음과 같습니다.
- 준수 요구 사항 충족 법적 개시를 위해 사서함 콘텐츠를 .pst파일로 내보낼 수 있습니다 .내보내기가 완료된 후 특별히 준수 목적으로 사용되는 사서함으로 콘텐츠를 가져올 수 있습니다 .
- 지정 시간 사서함 스냅숏 만들기 특정 사서함의 스냅숏을 만들면 사서함 데이터베이스의 전체 백업 세트를 유지하지 않아도 됩니다 .
- 사용자의 .pst 파일을 사서함 또는 개인 보관함으로 이동 Microsoft Outlook사용자는 전자 메일을 로컬에 .pst파일로 저장할 수 있습니다 .New-MailboxImportRequest cmdlet을 사용하면 사용자 .pst 파일의 데이터를 해당 사서함이나 개인 보관으로 이동할 수 있습니다. 이 방법은 사용자 로컬 컴퓨터에서 Exchange 서버로 전자 메일을 전송하는 편리한 방법입니다.
가져오기 및 내보내기 요청 사용 시의 이점
Exchange 2013에서 가져오기 및 내보내기 요청을 사용할 경우의 이점은 다음과 같습니다.
- Exchange 2013에는 .pst 파일을 읽고 쓸 수 있는 .pst 공급자가 포함되어 있습니다.
- 가져오기 및 내보내기 요청이 비동기적으로 처리됩니다. 큐 및 제한 프레임워크를 이용하는 MRS에서 프로세스를 수행합니다.
- .pst 파일을 사용자의 개인 보관으로 직접 가져올 수 있습니다.
- 여러 .pst 파일을 동시에 가져오거나 내보낼 수 있습니다.
- Exchange 서버가 액세스할 수 있는 모든 공유 네트워크 드라이브에 .pst 파일이 상주할 수 있습니다.
- Exchange 2013에서는 다음 .pst 파일을 지원합니다. Office Outlook 2007 및 Outlook 2010에서 생성된 유니코드 파일
고려 사항
사서함 데이터를 가져오거나 내보내기 전에 다음을 고려합니다.
- 사 서함 데이터를 가져오거나 내보내려면 Exchange 서버가 액세스할 수 있는 네트워크 공유 폴더를 설정해야 합니다. 사서함 데이터를 가져오고 내보내는 네트워크 공유에 Exchange Trusted Subsystem 그룹이 액세스할 수 있도록 이 그룹에 읽기/쓰기 권한도 부여해야 합니다. 이 권한을 부여하지 않으면 Exchange에서 대상 사서함에 연결할 수 없다는 오류 메시지가 표시됩니다.
- Outlook에서 지원되는 최대 .pst 파일 크기는 50GB입니다. 따라서 50GB보다 큰 .pst 파일은 가져오지 않는 것이 좋습니다. 50GB보다 큰 사서함의 경우 포함 또는 제외할 특정 폴더를 지정하거나 콘텐츠 필터를 사용하여 .pst 파일을 여러 개 만들 수 있습니다.
- 가져오기 및 내보내기 요청은 MRS에서 수행되며, 이동 요청과 사서함 복원 요청도 MRS에서 처리됩니다. 모든 요청은 MRS에 의해 대기되고 제한됩니다.
- 파일 크기, 네트워크 대역폭 및 MRS 제한에 따라 사서함 데이터를 가져오고 내보내는 데 몇 시간 정도 걸릴 수 있습니다.
- 공용 폴더 또는 공용 폴더 데이터베이스로 데이터를 가져올 수는 없습니다.
사서함 데이터 가져오기
MailboxImportRequest cmdlet 집합을 사용하면 .pst 파일의 데이터를 사서함이나 개인 보관으로 가져올 수 있습니다. .pst 파일에서 사서함 데이터를 가져올 때 지정할 수 있는 옵션 목록은 다음과 같습니다.
| 참고: |
| 데이터를 가져올 사서함이 존재해야 합니다. 사서함이 없는 사용자 계정으로는 데이터를 가져올 수 없습니다. |
- 데이터를 내보낸 계정이 아닌 다른 사용자 계정으로 데이터를 가져올 수 있습니다. 예를 들어 john@contoso.com에서 데이터를 내보낸 후 legaldiscovery@contoso.com으로 가져올 수 있습니다.
- IsArchive 매개 변수를 지정하여 사용자의 개인 보관으로만 항목을 가져올 수 있습니다.
- 관련 폴더 메시지가 .pst 파일에 있는 경우 AssociatedMessagesCopyOption 매개 변수를 사용하여 가져올 수 있습니다. 연결된 메시지에는 규칙, 보기 및 양식에 대한 정보가 있는 숨겨진 데이터가 포함되어 있습니다. 이 데이터가 .pst 파일에 있을 경우 보안 네트워크의 모든 메시지를 가져옵니다.
- IncludeFolders 또는ExcludeFolders 매개 변수를 사용하여 특정 폴더를 포함하거나 제외할 수 있습니다.
- ExcludeDumpster 매개 변수를 사용하여 복구 가능한 항목 폴더를 제외할 수 있습니다. .pst 파일에 복구 가능한 항목 폴더가 있는 경우 이 폴더는 기본적으로 가져오기 요청에 포함됩니다.
출처: <http://technet.microsoft.com/ko-kr/library/ee633455(v=exchg.150).aspx>
사서함 데이터 내보내기
MailboxExportRequest cmdlet을 사용하면 사서함 데이터를 .pst 파일로 내보낼 수 있습니다. 사서함을 하나 또는 여러 개 내보낼 수 있지만 한 번에 하나의 요청만 각 .pst 파일에 기록됩니다. 사서함 데이터를 .pst 파일로 내보낼 때 지정할 수 있는 옵션 목록은 다음과 같습니다.
- IsArchive 매개 변수를 사용하여 개인 보관 데이터를 내보낼 수 있습니다.
- ContentFilter 매개 변수를 사용하여 내보낸 메시지를 필터링할 수 있습니다. 메시지 콘텐츠, 첨부 파일, 보낸 사람, 받는 사람, 받은 편지함 범주, 중요도, 메시지 유형, 메시지 크기, 메시지가 전송, 수신 또는 만료된 시기를 기준으로 필터링할 수 있습니다.
- IncludeFolders 또는ExcludeFolders 매개 변수를 사용하여 포함하거나 제외할 폴더를 지정할 수 있습니다. Exchange 2013 사서함에서 데이터를 내보내는 경우ExcludeDumpster 매개 변수를 사용하여 복구 가능한 항목 폴더를 제외할 수도 있습니다.
- AssociatedMessagesCopyOption 매개 변수를 사용하여 관련 메시지를 내보낼 수 있습니다. 연결된 메시지에는 규칙, 보기 및 양식에 대한 정보가 있는 숨겨진 데이터가 포함되어 있습니다. 기본적으로 관련 항목은 .pst 파일에 복사되지 않습니다.
출처: <http://technet.microsoft.com/ko-kr/library/ee633455(v=exchg.150).aspx>